Сортування злиттям – це один з базових алгоритмів інформатики, сформульований ще в 1945 році великим математиком Джоном фон Нейманом. Беручи участь у «Манхеттенському проекті», Нейман зіткнувся з необхідністю ефективної обробки величезних масивів даних. Розроблений ним метод використовував принцип «розділяй і володарюй», що дозволило істотно скоротити час, необхідне для роботи.
Принцип і використання алгоритму
Метод сортування злиттям знаходить застосування в задачах сортування структур, що мають упорядкований доступ до елементів, наприклад, масивів, списків, потоків.
При обробці вихідний блок даних дробиться на маленькі складові, аж до одного елемента, який по суті вже є відсортованим списком. Потім відбувається зворотний збірка в правильному порядку.
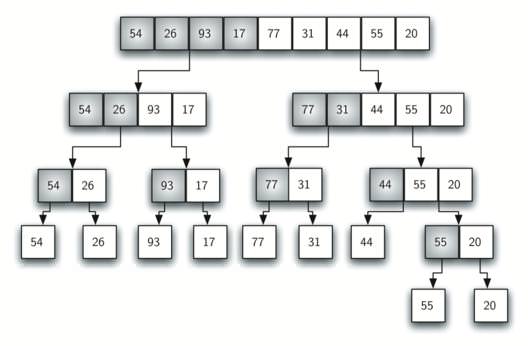
Для сортування масиву певної довжини вимагається додаткова область пам’яті аналогічного розміру, в якій по частинах збирається відсортований масив.
Метод може використовуватися для впорядкування будь-яких аналогічних типів даних, наприклад, чисел і рядків.