Сортування злиттям – це один з базових алгоритмів інформатики, сформульований ще в 1945 році великим математиком Джоном фон Нейманом. Беручи участь у «Манхеттенському проекті», Нейман зіткнувся з необхідністю ефективної обробки величезних масивів даних. Розроблений ним метод використовував принцип «розділяй і володарюй», що дозволило істотно скоротити час, необхідне для роботи.
Принцип і використання алгоритму
Метод сортування злиттям знаходить застосування в задачах сортування структур, що мають упорядкований доступ до елементів, наприклад, масивів, списків, потоків.
При обробці вихідний блок даних дробиться на маленькі складові, аж до одного елемента, який по суті вже є відсортованим списком. Потім відбувається зворотний збірка в правильному порядку.
Для сортування масиву певної довжини вимагається додаткова область пам’яті аналогічного розміру, в якій по частинах збирається відсортований масив.
Метод може використовуватися для впорядкування будь-яких аналогічних типів даних, наприклад, чисел і рядків.
Злиття відсортованих ділянок
Для розуміння алгоритму почнемо його розбір з кінця – з механізму злиття відсортованих блоків.
Уявімо, що у нас є два будь-яким способом відсортованого масиву чисел, які необхідно об’єднати один з одним так, щоб сортування не порушилася. Для простоти будемо впорядковувати числа за зростанням.
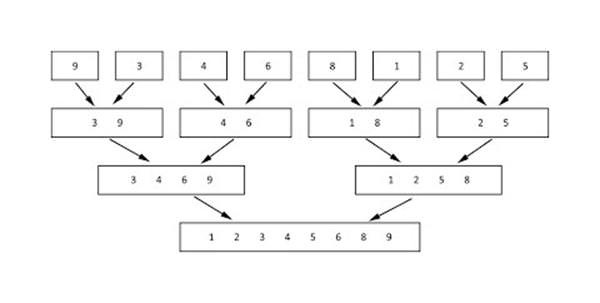
Елементарний приклад: обидва масиви складаються з одного елемента кожен.
int[] arr1 = {31};
int[] arr2 = {18};
Щоб злити їх, потрібно взяти нульовий елемент першого масиву (не забудьте, що нумерація починається з нуля) і нульовий елемент другого масивів. Це, відповідно, 31 і 18. За умовою сортування число 18 має йти першим, так як воно менше. Просто розставляємо числа в правильному порядку:
int[] result = {18, 31};
Звернемося до прикладу складніше, в якому кожен масив складається з декількох елементів:
int[] arr1 = {2, 17, 19, 45};
int[] arr2 = {5, 6, 21, 30};
Алгоритм злиття буде полягати в послідовному порівнянні менших елементів і розміщення їх у результуючому масиві в правильному порядку. Для відстеження поточних індексів введемо дві змінні – index1 і index2. Спочатку приравняем їх до нуля, так як масиви відсортовані, і найменші елементи стоять на початку.
int index1 = 0;
int index2 = 0;
Розпишемо по кроках весь процес злиття:
На першому витку ситуація буде виглядати так:
index1 = 0;
index2 = 0;
arr1[0] = 2;
arr2[0] = 5;
arr1[0] < arr2[0];
index1++;
result[0] = arr1[0]; // result = [2]
На другому витку:
index1 = 1;
index2 = 0;
arr1[1] = 17;
arr2[0] = 5;
arr1[1] > arr2[0];
index2++;
result[1] = arr2[0]; // result = [2, 5]
На третьому:
index1 = 1;
index2 = 1;
arr1[1] = 17;
arr2[1] = 6;
arr1[1] > arr2[1];
index2++;
result[2] = arr2[1]; // result = [2, 5, 6]
І так далі, поки в результаті не вийде повністю результуючий масив відсортований: {2, 5, 6, 17, 21, 19, 30, 45}.
Певні складності можуть виникнути, якщо зливаються масиви з різними довжинами. Що робити, якщо один з поточних індексів досяг останнього елемента, а у другому масиві ще залишаються члени?
int[] arr1 = {1, 4};
int[] arr2 = {2, 5, 6, 7, 9};
// 1 step
index1 = 0, index2 = 0;
1 2
result = {1, 2};
// 3 step
index1 = 1, index2 = 1;
4 < 5
result = {1, 2, 4};
//4 step
index1 = 2, index2 = 1
??
Змінна index1 досягла значення 2, проте масив arr1 не має елемента з таким індексом. Тут все просто: достатньо перенести залишилися елементи другого масиву в результуючий, зберігши їх порядок.
result = {1, 2, 4, 5, 6, 7, 9};
Ця ситуація вказує нам на необхідність зіставляти поточний індекс перевірки з довжиною сливаемого масиву.
Схема злиття упорядкованих послідовностей (A і B) різної довжини:
- Якщо довжина обох послідовностей більше 0, порівняти A[0] і B[0] і перемістити менший з них в буфер.
- Якщо довжина однієї з послідовностей дорівнює 0, взяти залишилися елементи другої послідовності і, не змінюючи їх порядок, перенести в кінець буфера.
Реалізація другого етапу
Приклад об’єднання двох відсортованих масивів на мові Java наведено нижче.
int[] a1 = new int[] {21, 23, 24, 40, 75, 76, 78, 77, 900, 2100, 2200, 2300, 2400, 2500};
int[] a2 = new int[] {10, 11, 41, 50, 65, 86, 98, 101, 190, 1100, 1200, 3000, 5000};
int[] a3 = new int[a1.length + a2.length];
int i=0, j=0;
for (int k=0; k a1.length-1) {
int a = a2[j];
a3[k] = a;
j++;
}
else if (j > a2.length-1) {
int a = a1[i];
a3[k] = a;
i++;
}
else if (a1[i] < a2[j]) {
int a = a1[i];
a3[k] = a;
i++;
}
else {
int b = a2[j];
a3[k] = b;
j++;
}
}
Тут:
- a1 і a2 – вихідні відсортовані масиви, які необхідно об’єднати;
- a3 – кінцевий масив;
- i та j – індекси поточних елементів масивів a1 і a2.
Перше і друге умова забезпечує те, що індекси не вийдуть за межі розміру масиву. Третій і четвертий блоки умов, відповідно, переміщують в результуючий масив меншого елемента.

Розділяй і володарюй
Отже, ми навчилися об’єднувати відсортовані колекції значень. Можна сказати, що друга частина алгоритму сортування злиттям – безпосередньо злиття – вже розібрана.
Однак необхідно ще зрозуміти, як від вихідного несортованого масиву чисел дістатися до декількох відсортованих, які можна буде злити.
Розглянемо першу стадію алгоритму і навчимося розділяти масиви.
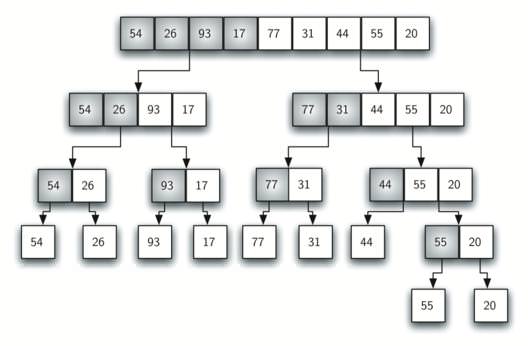
В цьому немає нічого складного – вихідний список значень ділиться навпіл, потім кожну частину також роздвоюється, і так до тих пір, поки не вийдуть зовсім маленькі блоки.
Довжина таких мінімальних елементів може бути дорівнює одиниці, тобто вони можуть самі по собі бути відсортованим масивом, проте це не обов’язкова умова. Розмір блоку визначається заздалегідь, а для його упорядкування може використовуватися будь-який відповідний алгоритм сортування, ефективно працює з масивами малих розмірів (наприклад, швидке сортування або сортування вставками).
Виглядає це наступним чином.
// вихідний масив
{34, 95, 10, 2, 102, 70};
// перший поділ
{34, 95, 10} і {2, 102, 70};
// друге поділ
{34} і {95, 10} і {2} і {102, 70}
Отримані блоки, що складаються з 1-2 елементів, дуже просто впорядкувати.
Після цього необхідно об’єднати вже відсортовані маленькі масиви попарно, зберігши порядок членів, що ми вже навчилися робити.
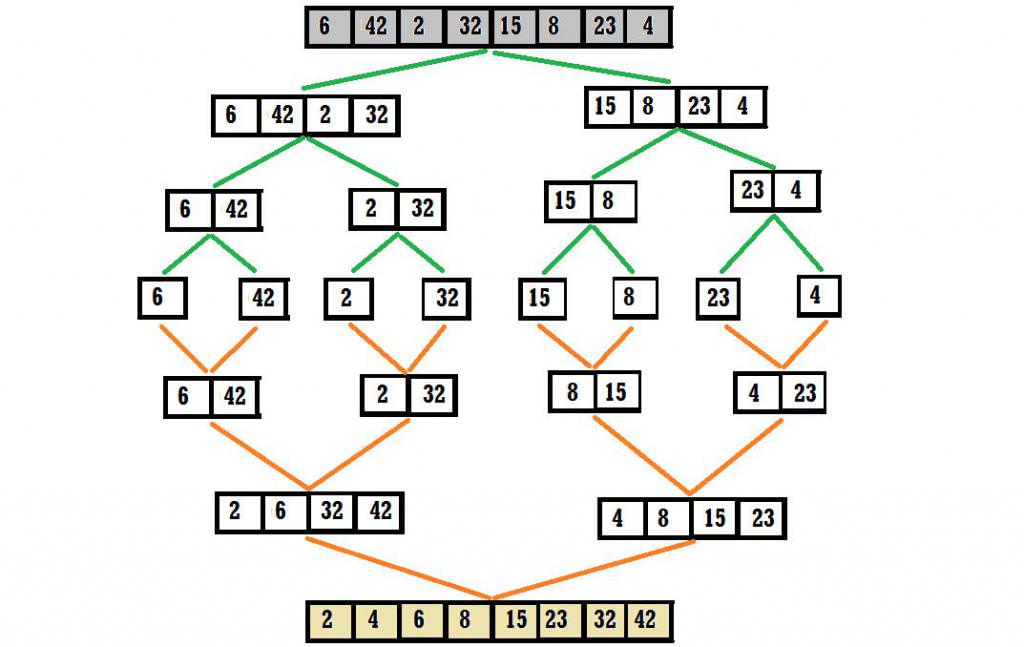
Реалізація першого етапу
Рекурсивне розбиття масиву показано нижче.
void mergeSort(T a[], long start, long finish) {
long split;
if (start < finish) {
split = (start + finish)/2;
mergeSort(a, start, split);
mergeSort(a, split+1, finish);
merge(a, start, split, finish);
}
}
Що відбувається в цьому коді:
Механіка роботи функції merge розглянута вище.
Загальна схема алгоритму
Метод сортування злиттям масиву складається з двох великих етапів:
- Розділити неотсортированный вихідний масив на маленькі частини.
- Зібрати їх попарно, дотримуючись правило сортування.
Велика і складна задача тут розбивається на багато простих, які послідовно вирішуються, приводячи до бажаного результату.
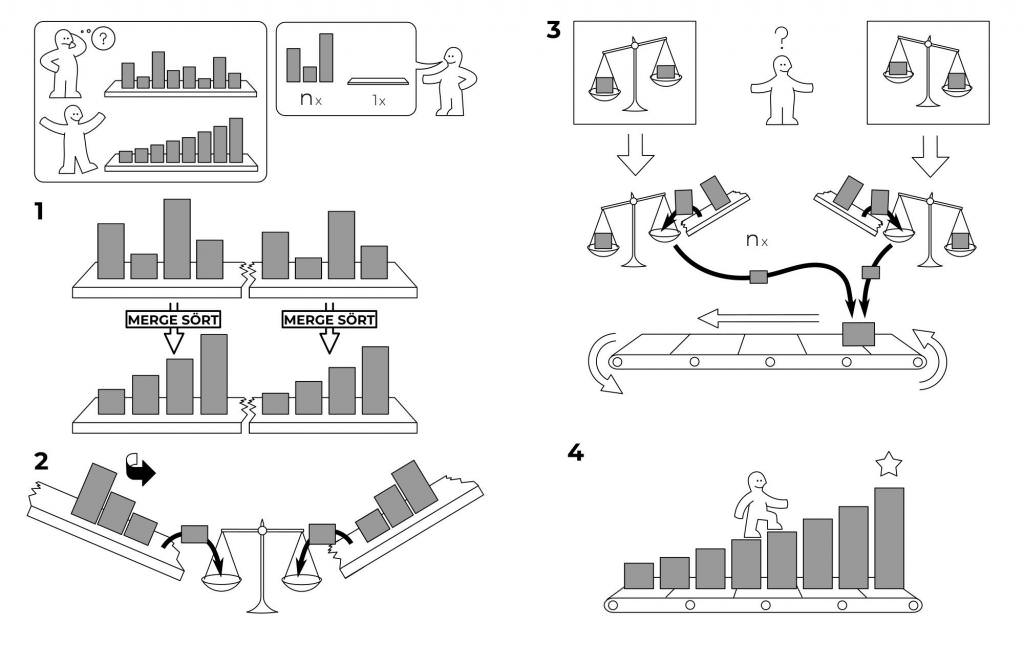
Оцінка роботи методу
Тимчасова складність сортування злиттям визначається висотою дерева розбиття алгоритму і дорівнює кількості елементів у масиві (n), помноженому на його логарифм (log n). Така оцінка називається логарифмічною.
Це одночасно і перевага, і недолік методу. Час його роботи не змінюється навіть у гіршому випадку, коли вихідний масив відсортований в зворотному порядку. Однак при обробці повністю відсортованих даних алгоритм не забезпечує виграш у часі.
Важливо відзначити і витрати пам’яті при роботі методу сортування злиттям. Вони дорівнюють розміру вихідної колекції. У цій додатково виділеної області з шматочків збирається відсортований масив.
Реалізація алгоритму
Сортування злиттям в Паскалі показана нижче.
Procedure MergeSort(name: string; var f: text);
Var a1,a2,s,i,j,kol,tmp: integer;
f1,f2: text;
b: boolean;
Begin
kol:=0;
Assign(f,name);
Reset(f);
While not EOF(f) do
begin
read(f,a1);
inc(kol);
End;
Close(f);
Assign(f1,'{ім’я 1-го допоміжного файлу}’);
Assign(f2,'{ім’я 2-го допоміжного файлу}’);
s:=1;
While (s
Зовнішня сортування даних
Дуже часто з’являється необхідність упорядкувати деякі дані, розташовані в зовнішній пам’яті ЕОМ. У ряді випадків вони мають значні розміри і не можуть бути розміщені в оперативній пам’яті для полегшення доступу до них. Для таких випадків використовуються методи зовнішніх сортувань.
Необхідність звертатися до зовнішніх носіїв погіршує тимчасову ефективність обробки.
Складність роботи полягає в тому, що алгоритм в кожен момент часу може мати доступ тільки до одного елемента потоку даних. І в цьому випадку один з кращих результатів показує саме метод сортування злиттям, який може порівнювати елементи двох файлів послідовно один за іншим.
Читання даних з зовнішнього джерела, їх обробка та запис в кінцевий файл здійснюються впорядкованими блоками (серіями). За способом роботи з розміром впорядкованих серій виділяють два види сортування: просте і природне злиття.
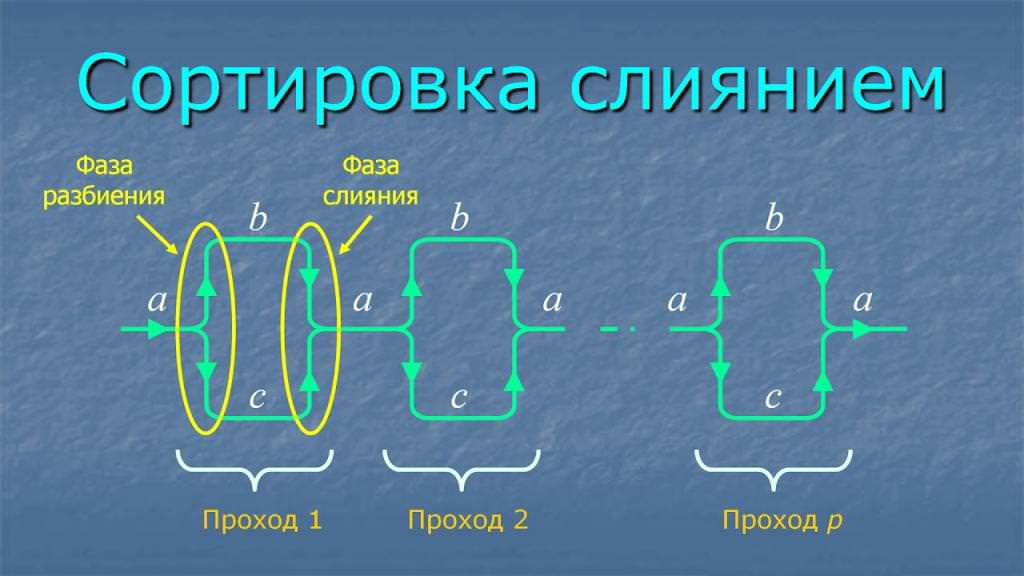
Просте злиття
При простому злитті довжина серії фіксується.
Так, у вихідному несортированном файлі всі серії складаються з одного елемента. Після першого кроку розмір збільшується до двох. Далі – 4, 8, 16 і так далі.
Працює це наступним чином:
Як зрозуміти, що зовнішня сортування простим злиттям завершена?
- нова довжина серії (після злиття) не менше загальної кількості елементів;
- залишилася всього одна серія;
- допоміжний файл f2 залишився порожнім.
Недоліки простого злиття наступні: так як довжина серій фіксована на кожному проході злиття, частково впорядковані дані будуть оброблятися так само довго, як і абсолютно хаотичні.
Природне злиття
Цей метод не обмежує довжину серій, а вибирає максимально можливі.
Алгоритм сортування:
З-за нефіксованого розміру серії доводиться позначати закінчення послідовності спеціальним символом. Тому при злитті збільшується кількість порівнянь. Крім того, розмір одного з допоміжних файлів може наближатися до розміру початкового.
У середньому метод природного злиття працює ефективніше в порівнянні з простим злиттям при зовнішній сортування.
Особливості алгоритму
При порівнянні двох однакових значень метод зберігає їх вихідний порядок, тобто є стійким.
Процес сортування може бути досить успішно розділений на декілька потоків.
На відео наочно продемонстрована робота алгоритму сортування злиттям масиву.